1週間経っていますが、JJUG CCC 2015 Springの講演資料を公開します。
「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」
追記(2015/5/25): PDF版も置きます。
# 「ありえるえりあ」の環境がひどすぎて、ファイルひとつアップロードするのもひと苦労です。なんでそんなひどいことになっているのか、外部の人には想像もできないでしょうが。
1週間経っていますが、JJUG CCC 2015 Springの講演資料を公開します。
「社長が脱RDBと言い出して困りましたが、開き直って楽しんでいる話」
追記(2015/5/25): PDF版も置きます。
# 「ありえるえりあ」の環境がひどすぎて、ファイルひとつアップロードするのもひと苦労です。なんでそんなひどいことになっているのか、外部の人には想像もできないでしょうが。
先日、社内勉強会でベンダーロックインではない Adaptive bitrate streaming 方式として MPEG-DASH (以下DASH) について紹介しました。
私自身、名前だけ知っていたものの、まだ先の話だろうと考えていました。勉強会向けにちょっと調べたらOS/ブラウザベンダーの足並みが揃いつつあります。まさに勉強会で一番勉強するのは発表者ですね。先の話どころか、いまいまの話でした。
新しいもの好きな方のために Chromecast も対応済です。MatchStick は未対応のようです。おそらくは Firefox の正式サポートを待ってからになるのかもしれません。
現時点では Adaptive bitrate streaming のデファクトスタンダードと言える HTTP Live Streaming を提供している Apple はどうでしょうか。
OS X Yosemite の Safari では対応しているようです。このニュースを Apple ではなく Adobe が報じているのもおもしろいです。iOS が DASH に対応するのか、するならいつ頃か?というのに注目が集まっています。
前置きが長くなりました。では早速ですが、DASH を試してみましょう。
ここでは、DASH の MPD スキーマを生成するために MP4Box というツールを使います。他にもいろいろなツールがあると思いますが、いくつか試してみた限りではこのツールが簡単でした。MP4Box をインストールするには、GPAC のダウンロードページを参照してください。私の環境 (Ubuntu 14.04) では、ソースをダウンロードしてきて make && make install で簡単にインストールできました。
MP4Box を使って DASH の MPD (Media Presentation Description) スキーマを作成します。ここでは10秒ずつセグメント化しますが、実際にセグメントファイルを作成するのではなく Range を定義しています。
|
1 |
$ MP4Box -dash 10000 -frag 1000 -rap penguin.mp4 |
以下の2つのファイルが作成されます。
|
1 2 3 |
$ ls penguin_dash.mpd penguin_dashinit.mp4 |
mpd ファイルの中身をみてましょう。こんな感じの xml ファイルが作成されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
<?xml version="1.0"?> <!-- MPD file Generated with GPAC version 0.5.1-DEV-rev5505 on 2014-11-17T01:02:21Z--> <MPD xmlns="urn:mpeg:dash:schema:mpd:2011" minBufferTime="PT1.500000S" type="static" mediaPresentationDuration="PT0H1M29.96S" profiles="urn:mpeg:dash:profile:full:2011"> <ProgramInformation moreInformationURL="http://gpac.sourceforge.net"> <Title>penguin_dash.mpd generated by GPAC</Title> </ProgramInformation> <Period duration="PT0H1M29.96S"> <AdaptationSet segmentAlignment="true" maxWidth="640" maxHeight="360" maxFrameRate="25" par="16:9"> <ContentComponent id="1" contentType="video" /> <ContentComponent id="2" contentType="audio" /> <Representation id="1" mimeType="video/mp4" codecs="avc1.42c01e,mp4a.40.2" width="640" height="360" frameRate="25" sar="1:1" audioSamplingRate="44100" startWithSAP="1" bandwidth="897663"> <AudioChannelConfiguration schemeIdUri="urn:mpeg:dash:23003:3:audio_channel_configuration:2011" value="2"/> <BaseURL>penguin_dashinit.mp4</BaseURL> <SegmentList timescale="1000" duration="9044"> <Initialization range="0-1313"/> <SegmentURL mediaRange="1314-1249497" indexRange="1314-1465"/> <SegmentURL mediaRange="1249498-2316777" indexRange="1249498-1249649"/> <SegmentURL mediaRange="2316778-3442186" indexRange="2316778-2316929"/> <SegmentURL mediaRange="3442187-4644676" indexRange="3442187-3442338"/> <SegmentURL mediaRange="4644677-5638462" indexRange="4644677-4644828"/> <SegmentURL mediaRange="5638463-6708750" indexRange="5638463-5638614"/> <SegmentURL mediaRange="6708751-7616222" indexRange="6708751-6708902"/> <SegmentURL mediaRange="7616223-9214725" indexRange="7616223-7616374"/> <SegmentURL mediaRange="9214726-9911855" indexRange="9214726-9214877"/> <SegmentURL mediaRange="9911856-10094227" indexRange="9911856-9911935"/> </SegmentList> </Representation> </AdaptationSet> </Period> </MPD> |
次にメディアプレイヤーとして DASH クライントの参照実装である dash.js を使います。
|
1 |
$ wget https://raw.githubusercontent.com/Dash-Industry-Forum/dash.js/v1.2.0/dash.all.js -O dash.all-1.2.0.js |
dash.js を使ってストリーミングを行うサンプルページを作ってみましょう。この html は dash.js の README で紹介されている方法です。
|
1 |
$ vim index.html |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<!doctype html> <html> <head> <script type="text/javascript" src="dash.all-1.2.0.js"></script> </head> <body> <h1>MPEG-DASH sample</h1> <div> <video id="videoPlayer" controls="true" /> </div> <script> (function() { var url = "http://localhost:8999/penguin_dash.mpd"; var context = new Dash.di.DashContext(); var player = new MediaPlayer(context); player.startup(); player.attachView(document.querySelector("#videoPlayer")); player.attachSource(url); })(); </script> </body> </html> |
これで準備が整いました。では実際にストリーミングしてみましょう。HTTP サーバーは何でも構いませんが、ここでは Python を使って HTTP サーバーを起動します。
|
1 |
$ python -m SimpleHTTPServer 8999 |
私の環境では IE11, Chrome38, Safari8 (on Yosemite) で再生できました。
リファレンス:
WebM も Mozilla のドキュメントを見ながら試してみたのですが、この内容では Chrome38, Firefox33 ともに再生できませんでした。たぶんやり方が変わっているのでしょうが、私がよく分かっていません。また機会があれば挑戦してみます。
UI のバグ報告などで、複雑な再現手順やちょっと気になるといった操作感を文章で伝えるのは難しいものです。そんなとき、スクリーンキャストを録画して、Trac 上で再生できれば便利ですね。
Trac Hacks を調べたところ、MovieMacro というプラグインがあったのでそれを紹介します。このプラグインは、Trac のチケットや wiki に動画共有サイトのプレイヤーを埋め込んだり、添付した動画ファイルを再生したりするためのマクロ (wiki 記法) を提供します。PyPI からもインストールできます。
https://pypi.python.org/pypi/TracMovieMacro
バージョン 0.3 の時点では、以下の動画共有サイトからプレイヤーを埋め込めます。
例えば、YouTube の動画を埋め込むときは以下のように記述します。
[[Movie(http://www.youtube.com/watch?v=9dfWzp7rYR4,style=width: 320px; height: 240px)]]
ただ Trac に外部の動画共有サイトにある動画を埋め込むのは、社内の利用だとあまり一般的ではないかもしれません。
さらに、添付ファイルを再生するのに Flowplayer というプレイヤーを使います。Flowplayer は商用サポートも提供しているメディアプレイヤーの老舗の1つです。商用ライセンスもありますが、GPL ベースのライセンスでも利用できます。
チケットや wiki に添付されたファイルなら単純にファイル名のみを記述するだけで使えます。
[[Movie(filename.webm)]]
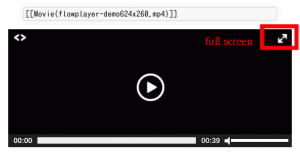
いろいろパラメーターを渡せるようにもなっているので詳細は Trac Hacks の MovieMacro のドキュメントを参照してください。よく使いそうな機能としては、右上のアイコンでフルスクリーン化したり、shift + ←→で再生速度を変えたりもできます。
対応フォーマットは以下になります。
スマートデバイスも html5 で再生できるんじゃないかと思っていましたが、いま手元にある iPhone5S で試したら再生できませんでした。スマートデバイス対応は不十分のようにみえます。
同僚によると、ブラウザ操作画面を録画するツールとして Screencastify (Screen Video Recorder) という Chrome 拡張が使いやすいようです。コンテナーフォーマットは WebM 形式で保存され、10秒ぐらいの操作を録画するとファイルサイズが1MiBぐらいになるそうです。Chrome や Firefox であればそのまま再生できますが、IE の場合は別途 WebM プラグイン (IE9+) をインストールする必要があります。
先日、社内でストリーミングの技術背景について勉強会をしました。
HTTP ストリーミングや HTML5 が身近なものとなり、スマートデバイスの普及によって古いブラウザを気にせずそれらの技術を享受できるようになりました。その動向の背景には、規格戦争があり、標準化や互換性やベンダーロックインがあり、直接的に技術とは関係ないエコシステムに翻弄されたりもします。そして、そういったものに振り回されるのは、体系的にいまの状況を把握できていないからだという自身の反省からまとめたものです。
たぶんこの資料は、これからストリーミング機能の開発を任せられた新人プログラマーが、どこを調べれば良いか、何ができて何ができないかを把握するのには適しています。足りない点も多々あるように思いますが、その先は自分で調べてください。また、このスライドを公開後に年月が経ってから見ると内容が古くなって適切ではない可能性が高いのでご注意ください。
パーフェクトJava第2版と同時発売になりましたが、監修をつとめた15時間でわかるJava集中講座を出版しました(技術評論社のページ))。
同時発売になったのは偶然で、本当は「15時間でわかるJava集中講座」のほうが先に発売する予定でした。色々あったのだろうと察してください。
どちらもJavaの本で同時発売ですが、棲み分け可能な本だと思っています。
昨日書いたように、「パーフェクトJava第2版」は、読者として一定の経験者を想定しています。Javaでなくてもいいので、なんらかの命令型言語の経験を想定しています。と言っても、if文とwhile文がなんとなく分かればいい程度ですが。
「15時間でわかるJava集中講座」は、元々、ワークスアプリケーションズ社の新卒研修のコンテンツが元になっている本です。このため、読者にプログラミングの経験を想定していません。
監修者なので客観的な評価ではないですが、「15時間でわかるJava集中講座」はなかなか良い本になっていると思います。Java8とEclipseがセットアップ済みの仮想環境(VMWareのイメージ)の入ったDVDが付属していて、知識ゼロの人がJavaを学び始められます。Javaの言語仕様だけではなく、Eclipseの使い方、JUnitの使い方、JAX-RSを使うWebアプリ開発の基本、果てはバグ報告の書き方まで説明しています。会社で使える実用知識を伝える新卒研修がベースだからこそのラインナップです。
自宅で妻が「15時間でわかるJava集中講座」を読み始めました。
妻はIT業界とまったく無縁です。ITに関して完全素人です。Bourneシェルとcシェルの違いすら区別がつきません。おそらくPCに入っているWindowsの種類すら把握していません。PCでWebブラウザ以外使っているのを見たことがありません。
そんな妻ですが、ワークスアプリケーションズ社では、プログラミング未経験の文系学生が「15時間でわかるJava集中講座」の内容で勉強を始めると聞いてやる気になりました。
放置して、どうなるかを見ていました。
「15時間でわかるJava集中講座」は、DVDに入っているVMWareのイメージを使って手を動かしながら読み進める本です。このため、最初に本の指示に従いVMWare Player(無料)をインストールする必要があります。これはできたようです。Windowsのインストーラは良くできています。
しかし次にひっかかりました。実は付属のVMWareイメージがzip圧縮されているのですが、サイズが大きすぎてWindows標準機能のzip解凍では正しく解凍できません。これは本に付属のQ&Aにも書いてありますが、やはり難しい壁だったようです。一応、Q&Aに従い7-zipをインストールしたようですが、解凍できないと言います。PCを見てみると、64bitマシンに32bit版の7-zipをインストールしてうまく動かなかったようです。使っているWindowsが32bitなのか64bitなのかを知るのは難易度が高すぎます。これは仕方ありません。
多少のヘルプをしましたが(VMWare Playerからの脱出方法など。これは知らないと無理です)、無事、VMWare Player上でCentOSが起動しました。当然ながら、妻にとって初のGNU/Linux体験です。
GNOMEがよくできているのか、本の誘導が良いのか、あるいは変な先入観がないからなのか、あっさりCentOS上で端末ソフト(gnome-terminal)もgeditもEclipseも使えています。
本に書いてあるとおりにコードを打ち込んで、端末ソフト上でjavacコマンドおよびjavaコマンドを実行する姿を後ろから覗いていました。打ち間違いがなかったようで無事にHello,Worldが表示されました。
しかし妻に反応がありません。初めてのHello,Worldに感動がないのでしょうか。動いたよと画面を指差しながら声をかけると、「ああ、これ」と反応します。「画面にぽんとHello,Worldが出ると思った」とのことです。ダイアログ画面を期待していたようで、端末ソフト上の表示を出力と思わなかったようです。この反応はその後に起きる話の伏線になっています。
「15時間でわかるJava集中講座」は、エラーなくHello,Worldの表示に成功した人に、あえてコードを打ち間違えて何が起きるかを確認するように誘導します。妻がgeditでprintlnをprintlに書き換えました。これでもう一度javacを打てばエラーになるはずです。
javacを実行するため、妻がなぜか新しい端末ソフトを開きました。思わず、元からあった端末ソフトのウィンドウを指差しながら、「これを使えばいいのに」と声をかけてしまいました。しかし、新しい端末ソフトで特に問題もないので、まあいいかとそのままにしました。この(自分から見ると)謎の行動も後の伏線になっています。
妻がjavacを打ち間違えてjaiacと書いてしまい、エラーになりました。打ち間違いを指摘するとすぐに気づきました。ここから謎の行動が始まりました。端末ソフトのウィンドウ上で、jaiacの部分をマウスでクリックし続けてはキータイプをします。
あまりの謎の行動に、思わず「何やっているの?」と聞くと「ここを書き換えたいのに書き換わらない」と答えます。
この瞬間、自分にアハ体験が訪れました。
妻に、コマンドプロンプトの表示が上に流れていくメンタルモデルがないことに気づいたからです。これで今までの(自分には謎の)行動の説明がつきます。コマンド行の下にHello,Worldが現れても表示と思わないこと。コマンドを打ち直すために、端末ソフトのウィンドウを新規に開いたこと。シェル上で打ち間違えたコマンドをその場で書き換えようとしたこと。
自分のように昔からコマンドラインに馴染んでいると、コマンドを打った後、出力が下方向に現れ、また入力や出力が画面の上に流れて行くのが普通に思っています。言わば、PCの画面をy軸でとらえるのが自然になっています。あまりにも普通すぎてそのようにしか画面を見ません。しかしそんな体験がない妻には、画面の内容が勝手に上に流れていく発想がありません。画面の反応は手前に来る、つまりz軸で画面をとらえているからです。
物理的に同じ画面を見ながら、こうも見方が違うものかと驚愕しました。
驚愕と同時に、世間的には自分のほうがマイノリティかもしれないと思うと、困ったものだと思わずにはいられません。
パーフェクトJava第2版を出版しました(技術評論社のページ)。
第1版出版から約5年経っての改訂版です。5年を長いと見るか短いと見るか微妙な年数ですが、Javaの世界ではこの期間に、Java7とJava8の2つのメジャーリリース、Java EE6とJava EE7のリリース、GUIライブラリの標準がSwingからJava FXへの変更と、(あまり動きがないと思われているJavaにしては)意外に変化がありました。
改訂2版の話を始めたのは、パーフェクトJavaScript出版後、2012年の初めでした。当時、改訂2版をJava8リリースに合わせて出すつもりでした。と言っても、2012年初めごろは、まだJava8リリース日が流動的だったので、実質何もしていませんでした。
2013年の間に、2014年初めのJava8リリースが確定情報になりつつありました。
しかし、なかなか執筆する気力がわきません。とりあえず2013年のJavaOneサンフランシスコに向けて、Java8のリサーチを始めて、JavaOneから帰って来たら執筆開始しようと心に決めていました。明日から本気出すみたいで、我ながら情けない話ですが。
サンフランシスコから帰国後、東京で行った2013年(去年)のJavaOne報告会で発表した時、Java8に対応した「パーフェクトJava第2版」を出しますと宣伝しました。と同時に、Java8リリースに合わせた出版が間に合いそうもないので、Java8リリースの遅延を望みます、とJava関係の場での発表とは思えない発言をしました。冗談めいていますが、実は本気でJava8リリースが遅れてくれないものかと思っていました。
Java開発陣はすばらしいもので、2014年の3月に無事Java8をリリースしました。もっとも、当初(がいつか分からないぐらい昔ですが)のプロジェクトラムダの計画からすると、Java8リリースはどれだけ遅れたのか、と言う気もしますが、もはや最初のリリース計画を誰も覚えていないのでどうでもいい話になっています。
結果としてパーフェクトJava第2版は、Java8リリースから9ヶ月遅れての出版となりました。もう3ヶ月ぐらいは前倒しで出版したかった思いもありますし、今年(2014年)の1月から4月あたりは猛烈に頑張って執筆していた記憶もあるので、9ヶ月遅れをなぜと思わなくもないですが、仕方ないですね。
書店に行くとJava本がだいぶ増えています。Java8に合わせて次の2つの系統の本が多く出版されています。
パーフェクトJava第2版は後者を志向しています。パーフェクトシリーズがそういう意図のシリーズだからです。このため、Java8の差分だけを効率的に拾いたい人にはコストパフォーマンスが少々悪い本かもしれません。買った場合、読む時の期待値を、後者に合わせて読んでください。
この話にも関連しますが、Java8の新機能をことさら特別扱いせずに説明しています。Optional型がかなり早い章(4章)にでてきます。新しい言語機能だから後に説明するという発想をしていません。たとえばOptional型であればnullと一緒に説明するほうが自然だという発想で書いています。
第1版に引き続きですが、ある程度プログラミングがわかっている人向けに書いたので、制御構文(if文やwhile文など)の説明は後回しにしています。結果として、if文より先にラムダ式を説明する本になりました。
第1版の自己評価では、「本屋で立ち読みするなら第4章がお勧め」と書きました。それは今回も変わりません。立ち読みが疲れなければ、第4章の後に「8章 ラムダ式とストリーム処理」を続けて読んでください。この2つの章を立ち読みするのはそれなりに疲れると思いますが。
技術評論社のページの目次を見ると、サーバサイドJavaがありません。Java EE7ベースで書いたサーバサイドJavaが書籍に入りきらなくなり、無料のPDFダウンロードになりました。詳しい顛末は書籍の前書きや後書きに書いたので興味があれば見てください。
ふたつほどごめんなさいがあります。
ひとつはJava8新機能の日付時刻ライブラリ(Date/Time API)をそんなに詳しく扱っていない点です。しかもどこに書いてあるのかわかりづらいです。「13章 列挙型と定数と不変型」に不変型の実装パターンの1例として日付時刻ライブラリに簡単に触れています。日付時刻ライブラリに関しては別途専門書が登場することを望みます。
もうひとつは第1章にあるイージーミスです。mainメソッドにstaticを書き忘れました。動くコードの例ではなく、サンプルコードの表記を説明する部分の記述です。あまりにイージーミスすぎて泣けてきますが、修正が間に合いませんでした。
先日 JavaOne 2014 サンフランシスコ報告会 Tokyo に参加したら CTO が発表していました。翌週、社内のグループウェアにそのイベント参加の所感を書きました。CTO の発表内容については、私がその内容に明るくないため触れませんでした。社内では、おおたにさんがいつも CTO をいじっているのですが (CTO は基本いじられキャラです)、それに馴染んできたのか、嘘でも良いからいじれと言われているような気がします。次回どこかで会ったらがんばって挑戦してみます。
閑話休題。アリエルでは課題/バグ管理システムの Trac を使っています。
Trac の安定バージョンがリリースされたので紹介します。
リリースノートによると、1.0.2 の修正チケットが全182件、そのうちリリースノート付きのチケットが167件とたくさんの改善が行われています。1.0.1 の修正チケットが25件であったため、1.0.2 が事実上の 1.0 系の安定バージョンだとみなすこともできます。社内では 1.0.2-trunk を定期的にアップデートしながらずっと使い続けてきました。特に問題なく、アリエルの用途では安定して運用できています。プラグインさえ対応していれば 1.0 より低い Trac バージョンからの移行に対する安心感が向上したと言えるでしょう。
リリースノートの日本語訳が公開されていたのでリンクを追加しました (2014-10-25) 。
せっかくの機会なので前回の記事からのアップデートをまとめます。
以前の記事の中でメンテナンスされていないプラグインは https://github.com/arielnetworks/ にて、自分たちでパッチ管理していると少し紹介しました。その中の1つに TracAutocompleteUsersPlugin というプラグインがあります。このプラグインはチケットのフィールドの入力中にユーザー ID を補完するものです。機能的に目新しいものではありませんが、あるのとないのではチケット登録時の利便性が全く違います。Trac 本体に取り込んでほしい機能でもありますが、いまのところはプラグイン拡張となっています。
便利なプラグインですが、長らくメンテナーが不在であったため、開発は停滞し、メンテナンスリリースさえ行われていない状態でした。アリエルでもいくつか機能拡張のパッチを提案していましたが、取り込まれる様子がないためにメンテナーになることにしました。威勢よく開発に取り組むつもりはありませんが、メンテナンスは積極的にやっていこうと考えています。いまは PyPI からもインストールできるようになっています。
メンテナーになった頃のものを 0.4.2 としてリリースしていました。また最近、新機能を2つ追加して 0.4.3 をリリースしています。それらを簡単に紹介します。
trac.ini に以下のようにカスタムフィールドのフィールド名を指定 (複数のときはカンマ区切り) すると、カスタムフィールドでも補完できるようになります。
|
1 2 |
[autocomplete] fields = qa_contact |
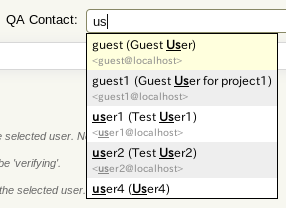
ドロップダウンリストであってもユーザー ID のみだと、同姓や同名のユーザーがいるとどちらなのか迷うときがあります。そんなときにユーザー情報 (例えば、姓名) が表示されると間違いが起きにくくなります。
以前の記事で Trac の新たな可能性の1つとして、Apache Bloodhound (以下 Bloodhound) を紹介しました。あれから3ヶ月ほどしか経っていないのであまり大きな動きはないようです。最新バージョン 0.7 のリリースが 2013-08-23 なので、それから1年以上、新しいバージョンがリリースされていないというのは、開発が停滞しつつあると言えるかもしれません。
メーリングリストで Bloodhound の開発状況についてどんな感じか聞いてみました。
回答してくれたのは Trac のコア開発者でもある Ryan Ollos 氏 (以下 Ryan 氏) です。彼は Bloodhound のコミッターでもあるようですね。やり取りの内容を要約します。
Trac 1.1.x (⇒ 1.2) でやろうとしているマルチプロジェクトは Multiple-Project, Multiple-Environment な戦略でやろうとしている。Bloodhound のマルチプロジェクトは Multiple-Project, Single-Environment で実現している。プロジェクト毎に DB を分けるか分けないかの違いがあるそうです。Ryan 氏自身は Bloodhound のマルチプロジェクト機能を Trac に backport したいそうですが、まだ具体的には何も決まっていないようです。
Ryan 氏は、もっと密接にして Bloodhound で導入した機能を Trac に backport していきたいと考えています。Bloodhound は Trac ベースのプラグインでしかないし、今後もそうあるように彼は考えています (fork しない) 。
開発者のメーリングリストの流量も減っていてやはり活発とは言えません。この3ヶ月であったことは GSoC を3件受け入れていたことぐらいかなと思います。これ自体は立派なことだと思います。
いまの状況をみる限り、Apache の top-level プロジェクトであっても開発者を確保するのは容易なことではないようにみえます。せっかく良さそうなものを作ったので、せめて upstream (Trac 本体) へ成果をマージするところまでがんばってほしいなと思います。
JavaOne 2014 サンフランシスコ報告会 Tokyoで、JavaOneの報告をしてきました。
Java EEの報告と言いながら、そのパートは上妻さんに任せて、Project AvatarとSpring Frameworkについて話しました。
JavaOneに行けばOracle社以外の話も聞ける、という事実は大事かと思います。
まさか会場にアリエルの森本さんがいるとは思っていなかったので、少しドキドキしました。
これが仮に大谷さんであれば、アリエル社内で、虚実いりまじった話をされるところです。森本さんはまともな人なので安心です。
以下にプレゼンに使った資料を公開します。
JavaOne2014に参加するためサンフランシスコに行ってきました。
過去のレポート記事(関連記事をたどるトップ記事)のリンクは下記になります。
JavaOne参加は、ここ5年で4度目です。毎回サンフランシスコの同じような場所を徘徊するので街の様子も慣れたものです。あまり馴染みのない東京のどこかの駅より、サンフランシスコのほうが土地勘があるぐらいです。
過去3回は自分でホテルも飛行機も予約していましたが、今回は金の力を使ってツアーで行きました。すべて手配してくれます。サンフランシスコ空港から市内へ行くのに、自分で電車に乗る必要がありません。考えてみると最近はそんな海外渡航が多い気がします。1年に1回ぐらいは自分ですべて手配して、現地の移動も公共機関を使わないと、自分がダメ人間になりそうです。
ホテルはユニオンスクエアを見下ろす場所にあるウェスティンでした。実に快適でした。ただ、ユナイテッド航空のサービスはお世辞にも満足とは言えません。3回中2回もバターが溶けた状態で出てきたのは、個人のミスではなく何か構造的な問題がある気がします。乗務員が食事の載ったトレイを軽々しく乗客の頭の上を通過させるのも気になりました。フェイルセーフの発想があればなるべく低い位置を移動させたほうがいいんじゃないかと、見るたびにずっと思っていました。そもそも乗務員のトレーの扱いが雑な印象です。向こうはプロなので自分の感覚が間違っているのかもしれませんが。とは言え、他の航空会社でこんなに何度も、機体が揺れたらあのトレー危ないな、と思うことはこんなにありません。扱いが雑だと感じたのは事実です。
キーノートを中心に今年の全体的な雑感を書きます。
今年のサンフランシスコは暖かったです。例年、昼間は暖かくても夜間が冷えます。今年は滞在した1週間のうち、夜の冷えを感じたのは1日だけでした。いつもは海からの寒風も加わり極寒になるトレジャーアイランドのコンサートも、今年は拍子抜けするほどの暖かさでした。今年が初参加となる何人かの人に、トレジャーアイランドのコンサートは寒いので気をつけろと事前に散々警告してきました。まるで自分が嘘つきだったみたいです。
なお、今年のトレジャーアイランドのコンサートのメインアーティストはエアロスミスでした。洋楽に詳しくない自分でもエアロスミスぐらいは知っています。知っている曲は1曲だけですが(映画アルマゲドンのテーマ曲)。
今年のJavaOneですが、ここ数年の中ではもっとも盛況に感じました。Oracle OpenWorldのキーノートスピーチの中で、スクリーンにJavaOne登録者数が9000人以上と出ていました。去年の入場者数は公式には発表されていないようですが、5000人から6000人という噂を聞いた記憶(あくまで非公式な噂なので正しいかは不明)があります。数字が正しければだいぶ増加しています。数字はともかく、個人の印象で、会場やキーノートにいる人の数が過去3回に比べて多く感じました。
逆にOracle OpenWorldのほうは人が減った印象でした。公式発表では、去年より登録者数が更に増えた(6万人以上)と言っていましたが。真相は不明です。数万の規模の人数になると、印象は当てにならないのかもしれません。
JavaOneのキーノートは、初日の日曜日と木曜日の2回です。初日のほうは公式色が強く、Oracle社の人が中心に登壇します。木曜日のほうはコミュニティキーノートというタイトルにもあるように少し非公式の印象になります。簡単に言って、前者のほうが堅く、後者のほうが緩い感じです。
堅めの初日キーノートは少々評判の悪いものでした。新しい発表がないのも一因ですが、司会が淡々としすぎて会場を盛り上げる感じがなかったからだと思います。Java8リリースという、近年のJavaの一大ニュースすら淡々と語り、会場がたいして沸かない有様です。
カーシミュレータのデモも最初から最後までまったく意味不明のまま終始しました。去年はチェスで盛り上がったけど今年はどう?という振りに、任せとけとばかりに始めた割に、ぐだぐだな印象でした。最初、デモが失敗して再起動しているように見えたのですが、壇上で何が起きていたか詳細は不明です。自分の英語力の問題かもしれませんが。
もっとひどかったのはIBMの発表です。ラジコンカーを会場でレースしてどちらが勝つかをアンケートしているようでしたが、何を言っているのか意味不明でした。Node-REDがスクリーンに載っていたので、この辺が関係していたのかもしれません。後はBlueMixの話をしていました。BlueMixはPivotal社のCloudFoundryをベースにしています。最近のIBMは、MongoDB、Riak、Chef、Node.js、Dockerあたりと提携なのか後押しなのかわからない関係を結んでいます。これらの技術の選定基準は不明瞭です。来るもの拒まずが基本スタンスなのかもしれません。
去年まではJava8のラムダ式を並列プログラミングの文脈で説明することが多かったのですが、今年は下記のように説明していました。このスタンスの変化は興味深いです。
Java SEのロードマップをMark Reihold氏とBrian Goetz氏という最近のJavaの技術の顔の両名が語り始めましたが、時間切れで説明が尻切れとんぼで終わりました。この説明は木曜日に持ち越されました。なお、Java EE8のほうは、HTTP2.0対応、JSON Binding、CDI2.0、MVC1.0あたりが注目です。
初日、JavaOneキーノートの後に同じ会場でOpenWorldキーノートがありました。
OpenWorldのキーノートの会場は例年どおりモスコーニです。去年より会場が狭くなった気がします。もし同じ広さだとしたらスクリーンの大きさや配置の変化で小さくなったと錯覚しているのかもしれません。JavaOneの初日キーノートも同じモスコーニですが、去年までは、JavaOneキーノートとOpenWorldキーノートで明らさまに広さが違いました。今年はあまり違いを感じませんでした。これは結構な驚きです。と言うのも、過去3回の経験では、OpenWorldのキーノートは圧倒的な広さと人の多さが印象的で、それに比べたJavaOneキーノートのしょぼさが際立っていたからです。
OpenWorldのキーノートと言えば、Larry Ellisonです。今年も健在、どころかここ数年で一番元気だった気がします。
今年のOpenWorldの一押しはOracleクラウドです。世間的にはクラウド一押しは別に珍しくもなく、どちらかと言うと遅いぐらいではないかという気がしますが、Larryにかかると違います。IaaS、PaaS、SaaSとクラウド3層すべてを提供しているのはOracleだけだと強調します。GoogleとMicrosoftも3層すべてを提供している気がしますが、Larryいわく、Oracleだけらしいです。何度も何度も自信満々にOracleのみ(we are only one)だと言い張ります。言ったもん勝ちです。たいへん勉強になります。
冷静に考えるとLarry Ellisonの今回のキーノート、意外に内容はありません。にも関わらず引き込まれます。冒頭、Oracleクラウドにより30年前からの約束を果たした、と言います。その約束が何かを明かさないまま話を引っ張ります。ようやく明かした約束は、ユーザアプリのソースコードを変える必要がない約束、というものです。なんじゃそれは、と椅子からずり落ちたくなるほどのネタです。オンプレミス環境とクラウド環境の間でアプリを移動する際、OSもミドルウェアも同じなので、アプリのソースコードを変える必要がないのは自明な気がします。しかしこれを30年前からの約束を果たした、と大きな物語にしてしまうのが流石です。勉強になります。
Oracleクラウドの説明は、SaaS、PaaS、IaaSの順でした。内容がある順に話した印象です。つまりSaaSに話すネタはたくさんありますがIaaSには特にないという感じです。
SaaSはOracleのFusionアプリをクラウド提供する話です。日本だとERPと大きくくくってしまうアプリ領域をOracleは、CX(Customer Experience)アプリ、HCM(Human Capital Management)アプリ、ERP(Enterprise Resource Planning)アプリと3分野に分類します。CRMやSFAなど顧客管理系アプリはCX、人事給与やタレマネなどの人事管理系アプリはHCM、会計やSCMなどがERP、という分類です。これがグローバル基準なのかOracle固有の分類なのかは不明です。
PaaSはWebLogicとOracle DBの組み合わせです。この環境にJava EEアプリをデプロイします。IBMはCloudFoundryベースで行くようですが(後述)、OracleクラウドでCloudFoundry対応の話は出ませんでした。Java EEの次期バージョンにPaaS対応の話題はあります。CloudFoundryと別路線になるのか、あるいはRedHat社と組んでOpenShiftを推すのか、あるいは結局CloudFoundryを取り込むのか、まだ決まっていないようです。
IaaSについてはほとんど言及がありませんでした。後で聞いた話ではまだOracle Linuxしか提供可能OSがないようです。OpenStackの言及はありませんでした。
技術的な話でOpenWorldで興味深いと思った話はSPARCプロセッサのM7の話です。どこまでやるかは不明ですが、JavaやOracleに都合の良い命令セットを持つという話です。一例としてデータ圧縮の復号処理やSQLの日付のbetween処理をハードウェアで実行する話をしていました。前者はともかく(インテルCPUが暗号処理をハードウェアで実行するのを考えると、データ圧縮の復号のハードウェア処理がそんなに奇抜とも思えません)、SQLの日付between処理はだいぶ奇抜に感じます。もちろんCPUがSQLを解釈するわけではなく、整数のbetween相当の処理、が本質だとは思いますが。
火曜日のキーノートにLarry Ellison再登場しました。
基本的にはOracleクラウドの話が中心ですが、SFDC(salesforce.com)への攻撃も忘れません。SFDCもOracle DBとJavaを使っているから、我々のプラットフォームが優れているのだという主張に加えて、しかしSFDCはプロプライエタリなPaaSだとばっさり切り捨てます。
もうひとつ興味深かったのは、Oracle(RDBMS)、NoSQL、Hadoopの3種類のデータソースに対して、どれにもSQLにクエリを投げられるOracle BigData SQLです。実態は不明です。
木曜日のJavaOneコミュニティキーノートは、初日に中途半端だったJava9の話が少しありました。Project ValhallaとProject Panamaです。
この中で今回フォーカスしたのが、Project Valhallaの中のValue typeの話でした。現状のJavaは、intやdoubleなどの基本型を敢えて無視して、オブジェクトと参照という世界に限定すると、ある意味、美しくて説明しやすい世界があります。ただ、ここには、美しさと引き換えに効率さを犠牲にしている側面があるのも事実です。この非効率さはコンパイラやJVMが裏で隠蔽していく流れだと思っていました。ここに来て、メモリレイアウトを意識させる言語仕様になるのは、抽象化の観点から見ると退行に感じます。Javaはアプリケーション記述言語からシステム技術言語へ立ち位置をシフトしていくのかもしれません。あるいは既にとっくにそういう流れかもしれませんが。
JavaOneコミュニティキーノートは去年からIoTが中心テーマです。更に今年目立ったのはロボットです。ALDEBARAN社も登場しました。サンフランシスコの地で、スクリーンにSoftBankグループの文字やPepperを見るとは思っていませんでした。
去年のJavaOneでIoTの連呼を聞いた時、正直、Java MEに未来があるとは思っていませんでした。客観的に見て、組み込み系の世界ではAndroidがJava MEの市場を奪っていると思えたからです。しかし、今年のロボット連呼を見ていると、少し考えが変わりました。ロボットのOSがすべてAndroidになるとは限らず、多様なOSが存在して、その上でJavaというのは、無いことは無い未来だからです。
コミュニティキーノートの後半は様々な事例が駆け足で発表されました。
RoboVMとlodgONによる、Java8とJava FX8をAndroidとiOSで動かす紹介がありました(Java FXPorts)。Dalvik VMはJava7だけど、我々のプラットフォームを使うといち早くJava8でAndroidアプリを書けると自慢していました。
これらに未来があるのか不明です。客観的には、Java FXで書いたアプリは、Windows、GNU/Linux、Macで動き、更にこれに加えてAndroidとiOSで動くので、かなり強力な選択肢と言えそうです。手離しで乗る気になれないのは、GoogleとAppleの両方から無視されている存在だからです。そもそもOracle OpenworldおよびJavaOneに来て思うのがGoogle無視の徹底ぶりです。裁判の関係とは言え、今、Google完全無視でITの世界を語ろうとすると、どうしても無理が生じます。
COMPANY Forum 2014に行ってきました。と言っても、セッションの1つにパネリストとして参加したので内部の人としてですが。
事前に登録者数1万人越えと聞いていたので、受付が大変な混雑になると思っていました。7月に品川であったAWS Summit Tokyo 2014も確か1万人規模の人が集まり、受付が相当に混雑したからです。しかし、当日、思ったより受付が整然としていました。COMPANY Forumの場合、2日間で1万人なので1日当たりの人数はAWS Summitに比べて少ないのでしょう。また、COMPANY Forumは会場が3カ所に分散していたせいもありそうです。
初日の午前はキーノートです。牧野さんの話(HUEの発表)は事前に知っている内容ですし、内部関係者みたいなものなのでコメントは控えます。その後、今回の目玉とも言えるスティーブ・ウォズニアック氏が登場しました(フロリダとのビデオ中継)。
ウォズニアック氏の印象ですが、一言で言うと、よく喋るな、です。牧野さんとの対談形式ですが、牧野さんの質問に1つに対して、ひたすら喋り続けます。とにかく止まらない。牧野さんも大変そうでした。
ウォズニアック氏の話の主張は、エンジニア中心主義を徹底していました。エンジニアだけが問題解決できる、イノベーションを起こしたければプロジェクトにエンジニアを入れるべき、と言った感じです。少々物事を単純化しすぎな気がしますが、そういうスタンスの人なのでしょう。
興味深かったのは、Apple社はGoogle社と比べてクローズドな会社ではないのかという牧野さんの質問です。それに対して、ウォズニアック氏が、自分自身はオープンを支持する人間だが、ジョブズは違うようだと回答したのは、正直で好感が持てました。そのままApple社の批判をしてくれれば主張に一貫性があってウォズニアック氏を讃えたいところですが、そうもいかず、全体としてはApple社擁護で終わりました(Apple社はオープンとクローズドをうまくバランスしている)。一貫してApple社のクローズドな姿勢を批判するFSFを見習ってほしいものです。
2日目は午前中に伊藤穰一氏と野茂英雄氏、夕方に安藤忠雄氏の講演を聞きました。どれも面白かったです。そして言葉に重みがあります。
しかし、みんな成功したから言える、という部分はあります。その辺を率直に語っていたのは野茂英雄氏でした。成功の秘訣なんてわからない、うまく結果を残せたから言えるだけだと。その点、安藤忠雄氏は成功の秘訣を聞かれ慣れたせいか、開き直って、ストレートにがんがん語っていました。普通のことやっても世界えは成功できないと。当然ですが、変わったことをすれば世界で成功できるわけではないのも厳然たる事実です。


最近のコメント