個人的に Python が熱いです。以前にも同じような事を言った気がしますが。多分デジャブです。
Python といえば、アリエルには言わずと知れた Python 界隈の大物が御座しますが。そんな大物の縄張りで、僕のようなチンピラがこれまた安っちい記事を書くのはかなり恐縮ですが。その辺りは気にせず、図太い精神で書いてこうと思います。
Python は、再帰の途中で内部状態を維持しつつ途中結果を返すジェネレータだったり、(mutable ながら)リストに対して map とか filter とか出来ちゃうところで Lisp を感じられる辺り、かなりオモロい言語です。
せっかくだし何か書きたいなという事で、ベクトル空間モデル [1] を使った類似文書検索プログラムを作ってみました。
出来たものだけ見せると、以下のように動作します。
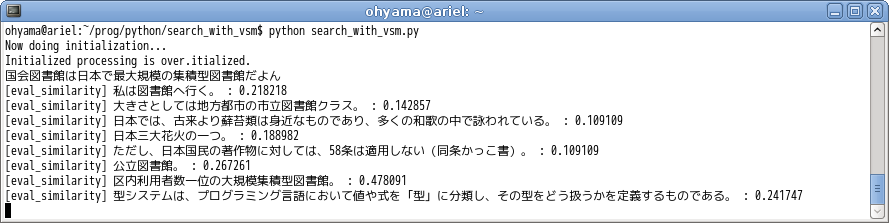
入力文書は標準入力から受け取ってます。4 行目の「国会図書館は…」が入力になります。結果に、入力文書が既知の文書に対してどれだけ似通ってるかの度合い (類似度) を 0 から 1 の範囲で示してくれます。
どうやって類似度を判定しているのかと言いうと。
その文書を特徴づける「何か」を何個か見つけて、そいつらを単位ベクトルに突っ込む処理を各文書に対して行います。
そして、それら個々のベクトルと入力文書を当該ベクトル空間にマッピングしたベクトルとの内積を取れば、既存の文書と入力文書がどれだけ似通ってるのかを数値化できます。
ご存知のとおり、内積はベクトル空間で直交した場合には 0 になりますし、各ベクトルの大きさの積で正規化してやれば、値を 0 から 1 の範囲にできるので、類似度を測るにはとっても便利な演算です。
この手法はかなり古典的ですが、特徴ベクトルさえ定義してやれば、文書の類似度判定だけでなく、顔認証や指紋認証といったあらゆる物理事象に対して応用できる、とってもオモロい手法です。
今回は Python の練習みたいなものなので、結果の正確性の検証や類似研究とかの比較は特にやってません。あしからず。
それでは早速やってみます。文書を特徴づける特徴ベクトルを「文書に含まれる単語」にします。一般に、機械学習の分野では「特徴ベクトルを定義しまくると結果の正確性が悪くなる」ということが知られています。
文書の類似度を算出する今回のプログラムにおいても、特徴ベクトルを規程する単語も、適当にいろんな単語を突っ込むよりも、その文書を特徴づけると思われる単語群 (類義語検索の分野では「有効語」とか言われているみたいです) を規程するのがベターです。
ここで問題が。文書の類似度を判定する為の特徴ベクトルを有効語とすると、文書から単語を取り出すプログラムが必要になってきます。
さすがにそこまで Python で自作する元気は無いので、既存の形態素解析ツール [3] を使わせてもらいました。
さて、材料は揃いました。以上をふまえて、文書の類似度を計測する Python プログラムを作ってみたの話。
[ (長くなったので) 次回に続く ]
[1] http://www.yc.tcu.ac.jp/~kiyou/no5/P099-109.pdf
[2] http://mecab.sourceforge.net/
最近のコメント