Document Actions
DHTからAmazon Dynamoまで
http://www.techno-brain.co.jp/careerlab/seminar/cloud_20100206/gaiyou.html でのプレゼン資料です。一部、書き直しています。
「技術屋目線でのクラウドの実際と今後」
「クラウドのスケーラビリティーを実現するアルゴリズム」
井上誠一郎 (アリエル・ネットワーク株式会社 CTO)
2010年2月6日(土)
今日、話すこと
DHT(Distributed Hash Table): 分散ハッシュテーブル と 周辺の話
自己紹介
井上誠一郎
- アリエル・ネットワーク株式会社 CTO (http://www.ariel-networks.com)
- ありえるえりあ (http://dev.ariel-networks.com)
- 執筆歴
- 「パーフェクトJava」
- 「P2P教科書」
- 雑誌「Software Design」「Emacsのトラノマキ」連載中
はじめに
そもそもDHTは何の分野の技術か?
- 分散探索技術のひとつ
- 検索やクエリー技術の文脈で語ることが多い
- 応用としての分散ストレージ(ファイル共有)
KVS(key-value store)の1分野と位置付けることも可能
用語
探す対象: バリュー、ファイル、コンテンツ、オブジェクト
探す時に使う文字列: キー、検索文字列、問い合わせ文字列
- 「キーID」という用語には特別の意味を持たせます
- 「検索文字列(キー)」から「キーID」を生成、という関係だと思って聞いてください
- ノードから「ノードID」を生成
DHTの先行研究; P2P由来
- Napster (1999年)
- 探索は中央インデックス
- Gnutella (2000年)
- 探索はフラッディング(flooding)
- Freenet (1999年)
- キーベースの探索(ハッシュ値が近いファイルが自動的に集まる)
GnutellaとFreenetのルーティングは下記を参照してください
DHTの先行研究; CARP
CARP(Cache Array Routing Protocol)
- URLからハッシュ値を計算して、使うWebキャッシュサーバを分散
- 1998年 Internet Draft: hash関数も具体的に定義
- squidなどが実装
DHTの先行研究; Plaxton構造
Plaxton構造 (1996年)
- 論文「Accessing Nearby Copies of Replicated Objects」
- key-value探索のデータ構造
- 詳細は後述(Pastry)
DHTの先行研究; Consistent hashing
Consistent hashing (1998年)
- 「Consistent Hashing and Random Trees」
論文は Webのキャッシュの負荷分散を想定
- vs. 普通のハッシュ関数(ノード数が変動した時の再計算で大量のオブジェクトが移動)
DHTの先行研究; Consistent hashing(2)
cf. 普通のハッシュ関数でCARPを動作する場合
- キャッシュサーバの台数5台の場合
- ハッシュテーブルのサイズは5
- ハッシュ関数の値域のサイズは5
- ハッシュ関数の例: module 5
- ノードが1台落ちると、ハッシュテーブルのサイズは4になる
- ハッシュ関数として module 4 を使うように変更
DHTの先行研究; Consistent hashing(3)
module 5のハッシュ関数を使うハッシュテーブルの例 7775 606 2387 3338 1999 1100 1201 1302 1003 994 |-----|-----|-----|-----|-----| 0 1 2 3 4
module 4のハッシュ関数を使う変更(ノード1台が離脱) 3338 1999 994 7775 606 2387 1100 1201 1302 1003 |-----|-----|-----|-----| 0 1 2 3
オブジェクトの移動が多い
DHTの先行研究; Consistent hashing(4)
rangedハッシュ関数
- 同じくキャッシュサーバの台数5台の場合
- ハッシュテーブルのサイズは5
- ハッシュ関数の値域のサイズを、例えば500にする
- ハッシュ関数の例: module 500
DHTの先行研究; Consistent hashing(5)
module 500、ハッシュテーブルサイズ5のrangedハッシュ関数を使うコンシステントハッシュテーブルの例
テーブルの各要素はハッシュ値100の範囲を受け持つ(0-99,100-199,200-299,300-399,400-499)
3338
666 7775 2387 1999
1003 1100 1201 1302 994
|-----|-----|-----|-----|-----|
0 1 2 3 4
module 500、ハッシュテーブルサイズ4のrangedハッシュ関数に変更(ノード1台が離脱)
テーブルの各要素はハッシュ値125の範囲を受け持つ(0-124,125-249,250-374,375-499)
3338 1999
1100 1201 1302 994
1003 666 7775 2387
|-----|-----|-----|-----|
0 1 2 3
注意: Chord(DHT)では、正確に 1/N の範囲を受け持つわけではありません
DHTの先行研究; Consistent hashing(6)
Consistent hashing関数に必要な性質
- smoothness: ノードの増減に対して、オブジェクトの移動が少ない
- spread: 空間に対してノード数が充分に少ない
- load: ノードあたりのオブジェクト数が少ない
(論文中で)数学的に厳密な定義はしていない
- ranged hash function: 具体的関数のひとつという位置づけで言及
DHT; 大雑把な理解
元々の問題「検索文字列から何かを探す」
- 検索文字列のハッシュ値計算 => 検索キー
- ノードのハッシュ値計算(上と同じハッシュ関数)
- 検索キーとノードを同じ空間上に配置(距離を定義)
- 「検索文字列の探索問題」が「検索キーに近いノードの探索問題」に
- 「距離」の縮め方がアルゴリズムの肝
DHT; 大雑把な理解(cont.)
- 各ノードは全体知識を持たない前提
- この前提で、各ノードが対称的に協調動作して探索
- 技術的には、近い所は良く知っていて、遠い所も少し知っている状態を「どう作るかと、どう維持するか」がポイント
- 探索を投げるごとに探索範囲は狭くなる。探索範囲が1/nずつ狭まっていけば、探索時間はO(log)になる
DHT
論文発表は2001年から2003年がピーク
DHT(2)
アルゴリズムの発表ピークの後は、概念の整理の論文多数
- structured P2P
- overlay network
- ALM(application level multicast)
- decentralized network
- key-based routing (KBR)
- rfc4981
DHTの代表的アルゴリズム
- Chord
- Content Addressable Network(CAN)
- Pastry
- Tapestry
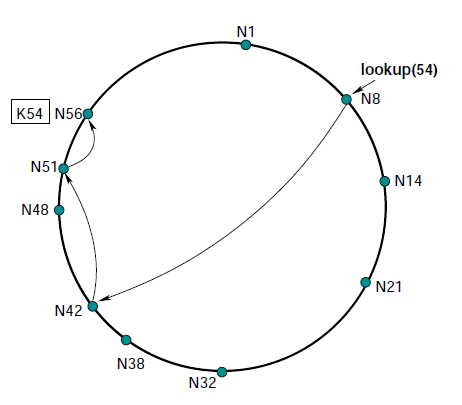
DHTの代表的アルゴリズム; Chord
- スキップリストで距離を定義
- ranged hash function
DHTの代表的アルゴリズム; Pastry
- 基数と桁数を決めて、prefix一致長で距離を定義
- n桁d進数の場合: 各ノードは n行d列の経路表を保持
- 経路表の i 行目: 自ノードIDとi桁目までprefixが一致したノードID
- 経路表の j 桁目: i+1桁の数字が j になるノードID
- 128bit
DHTの応用と実用
- Kademlia (BitTorrentなどが活用)
- Overlay Weaver
- 範囲検索
- DHTの拡張: PHT(prefix hash tree)
- 非DHT: Skip Graph
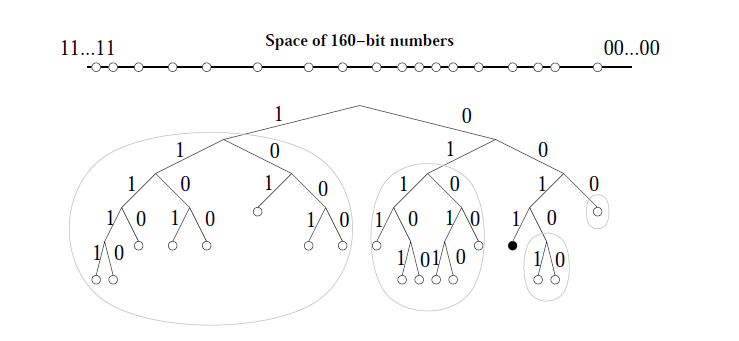
DHTの応用と実用; Kademlia
- XOR(binary tree)で距離を定義
- 160bit
- 経路表が対称なので、探索のついでに経路表の更新が可能
- BitTorrentのトラッカー探索にも使われる
DHTの応用と実用; Kademlia(3)
+-----------------+
| |
| |
+--------+ +--------+
| | | |
| | | |
+----+ +----+ +----+ +----+
| | | | | | | |
| | | | | | | |
000 001 010 011 100 101 110 111
Kademliaのルーティングは下記を参照してください
DHTとクラウド
Amazon Dynamo
Amazon Dynamo; 概要
- 既存技術の良いところ取り
- DHTs, consistent hashing, versioning, vector clocks, quorum, etc.
Amazon Dynamo; DHT?
マルチホップをしないDHT(性能要求のため): zero-hop DHT
- Chordと同じConsistent hashing
- 各ノードは必要なルーティングテーブルを保持 (ノード総数はそんなにスケールしない): preference list
- ノード数は数百のオーダー
- ネットワークは充分に速いという前提
Amazon Dynamo; DHT? (2)
- ノードをリング上の複数箇所にマップ: "virtual nodes"
- キーIDは、検索文字列のMD5値(128bit)
- ノードIDはランダムに選択(ノード総数を把握している前提で均等化。CARPに近づいている?)
Amazon Dynamo; DHT? (3)
- 一般的なP2Pでは「churn耐性(ノードの変動への耐性)」が重要
- Dynamoはchurnに対してあまり頑張っていない
Amazon Dynamo; DHT? (4)
gossipベースのプロトコルでノードの参加と離脱のアナウンス
- 一定インターバルで、各ノードがランダムに選んだノードに最新情報をpush
- 定数Nを決めておき、既に最新情報を取得済みのpush先がN件現れると、その情報のpushをやめる
- 情報伝達の速度はあまり速くない(はず)
Amazon Dynamo; DHT? (5)
quorum(投票)ベースで、(ノード故障による)ビザンチン障害に対応
- read(get)、write(put)時に指定した数のノードが成功するまで待つ
- デフォルト値は、3つ投げて2つ以上成功で成功((N,R,W)=(3,2,2))
- 参照処理の性能を上げたい時は、readのquorum値(R)を1に指定
ノードは(故障することはあるが)信頼はできると仮定
Amazon Dynamo; 分散ストレージ
プログラマブルインターフェース(API)
- get(key)
- put(key, context, object); // context:メタデータ(バージョン含む)
Amazon Dynamo; 分散ストレージの課題(2)
コンフリクトへの対応
- cf. optimisticアプローチ。write側にconflict解消の責務を負わせるシステムが多い(readは決して失敗しない)
- Dynamoは、readに負わせている(writeは決して失敗しない)
- しかし、Dynamoも責務を(上位)アプリ層に丸投げしているだけ
Amazon Dynamo; 分散ストレージの課題(3)
コンフリクト時の戦略(上位層)
- "merge" or "last write wins"
- 基本的には"merge"しているらしい。たとえばショッピングカートの "add to curt" は失わせないマージ
- (一部)下位層での "read repair"
Amazon Dynamo; vector clocks
vector clocks: (node,counter)ペアのリスト。counterはそのノードでのオブジェクト更新時刻
version-a version-b (node-1,count) (node-1,count) (node-2,count) (node-2,count) (node-3,count) (node-3,count) 全count値を比較 => すべてが less-than-or-equal なら、そちらが古い。 それ以外はconflict
vector clockのサイズ問題 => 大きくなりすぎると古いクロックペアを取り除く
Amazon Dynamo; 分散ストレージの課題(5)
conflict検出を素早く行うために Merkle tree を利用
=> ウソでした。リビジョンのずれではなく、保有するキーの一覧のずれ(要はレプリケーションのずれ)を検出するため
Amazon Dynamo; Merkle tree
- 複数オブジェクトのリビジョンのずれを素早く検出するために利用 => ウソ。前ページ参照
- リーフの値がキーのハッシュ値
- 親ノードの値は子ノードの値(ハッシュ値)の連結値のハッシュ値
- ツリーのルートからチェック(最初はルートノード値だけ交換)
- 各ノードは一定キーレンジに対してMerkle treeを保持
Amazon Dynamo; 実装メモ
- ストレージは既製を利用(Berkley DB, MySQL, in-memory buffer)
- 各ノードにrequest coordinatorプロセス (クライアントの代わりに分散処理。クライアントにやらせる方が高パフォーマンス)
まとめ
- 分散技術のアイディアの源泉をたどりました
- 実用システムでは、細かい工夫の積み重ねが重要