Document Actions

冠詞(aとthe)のプログラマ向け説明
アリエルでは毎週金曜に英語勉強会を開催しています。勉強会のつもりで始めましたが、事実上、完全に先生ひとり、生徒多数の状態になっています。ただし、先生はアマンダではありません。
先週、先生から冠詞(aとthe)の間違いを指摘されました。aと書くべき場所でtheと書いてしまったためです。先生はそこでtheは自然ではない、と言います。日本人には何が自然か分かりません。結局、先生も説明に苦労していました。
冠詞は日本人にとって鬼門ですが、プログラマにとっては馴染みの概念で説明できる気がしてきました。冠詞aは自由変数、冠詞theは束縛変数、を示す記号だと説明するのです。
教材に使っているLinusのスピーチから引用してみます。
http://git.or.cz/gitwiki/LinusTalk200705Transcript
I am instead talking about git, which is the source control management system that we use for the kernel.
この文にはふたつのtheがでてきます。最初のtheは"source control management system"に付随しています。この文脈では、これはgitという実体に束縛されています。なのでtheです。2番目のtheはkernelについています。これは文脈上、Linuxという実体に束縛されています。一般的なkernel、つまり特定の実体に束縛されていない、という文脈であれば、"the kernel"は"a kernel"になります。複数形(プログラマ的にはコレクション)にtheが付くルールも同じです。複数のkernelたち、要素は自由変数、という気持ちであれば"kernels"になります。一方、LinuxとSodexのように束縛された変数(シンボル)を束ねた気持ちであれば"the kernels"になります。
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/a-the-for-programmer/tbping
0と1、どちらから数えるか
Smalltalkの配列のインデックスは1から始まる、と本に書いてありました。また別の本によると、VB(Visual Basic)のCollectionも1ベースのようです。
現在のメジャーなプログラミング言語の多くでは、配列のインデックスは0から始まります。時々、プログラミング初学者から、なぜ0から数えるのですか、と質問されます。0から数えるのが習慣になってしまい、疑問すら抱かなくなっている人間には新鮮な疑問です。
なぜ0からか、には、全てのビットがゼロの値を無駄にしたくないから、と答えます。今となっては、昔からの慣習だから、もひとつの答えです。
8ビットで考えると、ビットがすべてゼロの値(プログラミング言語レベルでは数値0)をインデックスに使うか使わないかで、配列を256個までアクセスできるか(0から255)、255個までアクセスできるか(1から255)の差がでます。この1個の差は大きいので無駄にはできません。32ビットになれば、配列の先頭要素を捨てたところでたいして痛くもありませんが。
ここまでの話は、配列が連続したメモリ領域で、インデックスはメモリ領域内のオフセットに対応した値、という前提での話です。リンクリストなどは前提が異なるので、1から始めて悪いか、と開き直られると、別にいいんじゃない、としか答えようがありません。
1から数える、と言えば、Emacsのバッファ内のポイントがあります(参考 http://dev.ariel-networks.com/Members/sugawara/emacs-lisp-52c95f374f1a-30c330d530a1306830a630a330f330a67de8)。
Alan Kay(Smalltalkの作者)は初心者相手に媚を売ったのかもしれませんが(真相は不明)、rmsが初心者に媚を売ったとは思えません。何か理由があるのかも、と勘ぐりました。バッファの先頭バイトを何か別の用途に転用しているとか。勘ぐると、ありそうな気がしてきます。
結論から言うと、バッファの先頭バイトを別の用途に使ったりはしていません。先頭バイトを捨てているわけでもなく、(プログラマに見せる)ポイント値(1から始まる)から、内部のメモリ領域のオフセット(0から始まる)にするために、毎回、1を引いています。コードで言うと、次のような感じです(emacs-22.1から引用)。
/* editfns.c に point関数の実体 */
DEFUN ("point", Fpoint, Spoint, 0, 0, 0,
doc: /* Return value of point, as an integer.
Beginning of buffer is position (point-min). */)
()
{
Lisp_Object temp;
XSETFASTINT (temp, PT);
return temp;
}
/* PTの定義はbuffer.hに以下 */
/* Position of point in buffer. The "+ 0" makes this
not an l-value, so you can't assign to it. Use SET_PT instead. */
#define PT (current_buffer->pt + 0)
/* PTの初期化はbuffer.c内のget-buffer-create関数内 */
DEFUN ("get-buffer-create", Fget_buffer_create, Sget_buffer_create, 1, 1, 0, 略)
(name)
register Lisp_Object name;
{
...略
BUF_PT (b) = BEG;
/* マクロBUF_PTとBEGはbuffer.hで以下のように定義 */
/* Position of point in buffer. */
#define BUF_PT(buf) ((buf)->pt)
/* Position of beginning of buffer. */
#define BEG (1)
#define BEG_BYTE (BEG)
マクロだらけで少し分かりづらいですが、elispレベルで (point) 関数を呼ぶと、内部的にはPTの値が返るだけです。このPTは最初に1(BEG)で初期化されています。これを見た時、内部的に確保したメモリ領域のオフセット1バイト目以降をバッファとして見せているのだと思いましたが、実際には次のようにBEG_BYTE(=1)を引いています。
/* Return the address of byte position N in current buffer. */ #define BYTE_POS_ADDR(n) \ (((n) >= GPT_BYTE ? GAP_SIZE : 0) + (n) + BEG_ADDR - BEG_BYTE)
マクロに隠蔽しているとは言え、この手のBEG_BYTEによる調整コードが意外にあるので、バグの元に見えて気持ち悪いです。
結局、ポイントを1ベースにするメリットはコード上からは全く分かりませんでした(デメリットはBYTE_POS_ADDRにあるような、REG_BYTEを引く処理)。謎です。
まったく別の話ですが、上のPTについた "+ 0" のテクニックは良いです。PT = 1のような代入式をコンパイルエラーにするための小細工です。+0 はコンパイルの最適化で消えるので、性能劣化はありません。
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/from-zero-or-one/tbping
trac派に転向?
社内でtracを使っています。
普段、UIのぱっと見の綺麗さをほとんど評価対象にしないのですが、正直、このUIはいかがなものか、と思うUIです。唯一、tracで評価しているのが、SQLを直接書けるTracReport機能です。もっとも、以下のマニュアルページ(http://trac.edgewall.org/wiki/TracReports)を見ると、次のように書いてあります。
Note: The report module is being phased out in its current form because it seriously limits the ability of the Trac team to make adjustments to the underlying database schema. We believe that the query module is a good replacement that provides more flexibility and better usability.
要は、SQL直書きのTracReport機能は推奨しない、ということです。作り手側の意見として、SQL直書き機能が足かせになるのは理解しますが、query module(GUIでプルダウンメニューを選ぶUI)の方がflexibleという主張は納得できません。
TracReportを除けば、tracはbugzillaの出来損ない、という印象でした(RDBのテーブル設計も似ています)。
しかし、WebAdmin(http://trac.edgewall.org/wiki/WebAdmin)がプラグイン、という事実を知って見方が変わりました。他の人が色々セットアップした後からしか見ていないので、この辺の事情を知りませんでした。一見、基本機能のように見える部分までプラグインとなると、tracは侮れません。知らずに、見た目だけで軽率な評価を下していたことを反省しました。
最近、trac以外に、外部ユーザの作った機能に、大胆に画面を侵蝕させるシステムをいくつか見ました。SalesforceのAPEXとfacebookです。tracを含めて3つに共通するのが、画面が結構しょぼいことです。主観的評価ですが、画面にリッチ感がありません。しかし、それゆえにか、外部ユーザの作った(UIに凝っていない)機能が画面に侵蝕しても、あまり違和感がありません。結果、外部ユーザの参入障壁が下がる、外部アプリが増える、という好循環が起きている気がします。周りのUIがリッチすぎると、こうは行きません。さしずめ、Web UI版、悪い方が良いの法則を見た気がします。
推奨しないと書いてありますが、それでもTracReportは便利です。subversionのコミットログもRDBに入っているので、subversionの統計処理にも使えます。プロジェクトマネージャーみたいなことをしていると、この手の統計情報が欲しくなります。過去、bugzillaやmantisでは、バイト学生にPerlやPHPで統計処理を行うプログラムを書いてもらっていました。tracであれば、SQLを書くだけです。
以下にsqliteがバックエンドの時のTracReportのSQLを書くtipsを書きました。
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/trac-fan/tbping
ローテクなメモリ使用量監視方法
GNU/Linux上のプロセスのメモリ使用量のローテクな監視方法です。 必要なのはシェルとgnuplotだけです。
シェルはこんなコードです。 やっていることはprocファイルシステムのstatmファイルの中身を一定期間ごとに読み出すだけです。 statmファイルの中身の意味を覚えたりはしないので、コードのusage出力に書いておきます(Linuxのソースコードからコピー)。 コマンドの使い方は変に文書化するより、このようにコマンド自体にしゃべらせる方が利便性と保守性に優れています。
メモリリークを調べるには、先頭カラム(size)の量を監視すれば充分です。 2番目のカラム(resident)は、RSSとも略されるメモリ使用量で、(そのプロセスが)実メモリを占めているメモリ使用量です(sizeは仮想メモリ上のメモリ使用量。ページアウトされた分も含みます)。
#!/bin/sh
export LANG=C
if [ "x"$1 = "x" ];
then
echo "usage: $0 pid-to-watch"
echo "usage example: $0 \`pidof process-name-to-watch\` | tee /tmp/mem.log"
echo "output:# sprintf(buffer,\"%d %d %d %d %d %d %d\\n\""
echo " size, resident, shared, text, lib, data, 0)"
exit
fi
pid=$1
while :
do
echo -n `date '+%Y-%m-%d-%H:%M'` ' '
cat /proc/${pid}/statm
sleep 1m
done
出力を適当なファイルに書き出して、gnuplotでグラフ化します。 そのためのスクリプトは次のようになります。
set xdata time set timefmt "%Y-%m-%d-%H:%M" set format x "%H:%M" # set xrange ["2007-12-11-16:00":] plot "/tmp/watch-mem.log" using 1:2 with lines
コメントアウトしている set xrange の行は、見たい範囲を限定したい時に使います。 iceweaselのメモリ使用量のグラフは次のようになりました。
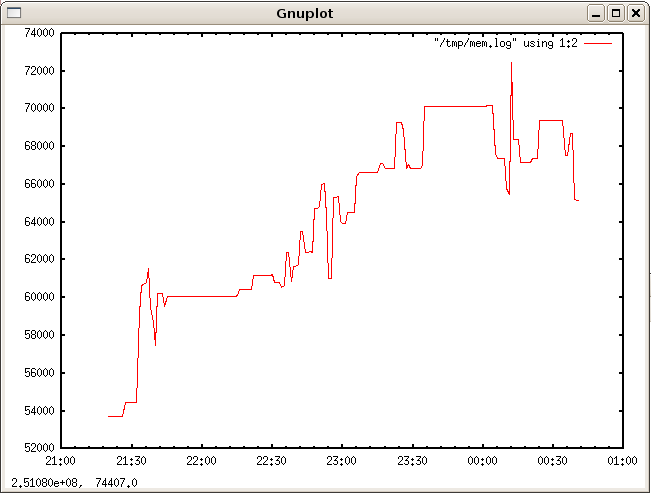
メモリリークを調べたい時は、このグラフと(対象プロセスの)ログをつき合わせます。 こんなローテク、役に立つのか疑問に思うかもしれませんが、ハイテク(LeakTracer,ccmalloc,Valgrind,mpatrol)で見つからなかったメモリリークのバグの箇所を見つけられました。単にハイテクを使いこなせていないだけ、という噂もありますが。
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/low-tech-to-watch-memory/tbping
クリスマスプレゼント
AirOne v4.8.3でました。
- http://www.ariel-networks.com/blogs/airone/2007/12/av483.html
- http://www.ariel-networks.com/blogs/airone/2007/12/v483.html
一部の動作が10倍以上速くなっています。まあ、単にバグっていただけですが。
時々、ソフトウェアの新リリースの紹介で、数倍や数十倍の速度向上を誇らしげに書いてあることがあります。たいていは元がへぼいだけです。しかし、そこに突っ込まないのが大人のマナーです。リリースのたびにそんなにパフォーマンスが向上するなんて、まるでJavaのようですね、と褒めてあげてください。
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/airone483/tbping
Rails2 on Debian/etch
開発版を追いかけるのは疲れるので、安定版がリリースされるまで待ちます。Rails2もようやくいれてみました(*)。
etchでパッケージ化されているrailsは次のバージョンです。
$ dpkg -l|grep rails ii rails 1.1.6-3 MVC ruby based framework geared for web appl
これは古すぎるので、以前、/usr/local/ruby以下にrails1.2.5をインストールしていました。 その時の手順は次のようにしました。
# aptitude install rubygems # mkdir /usr/local/ruby # chown inoue:users /usr/local/ruby $ gem install rails -i /usr/local/ruby --include-dependencies
/usr/local/rubyの所有を自分にしてgemの実行をroot権限で行わない理由は、gem install がシステム領域(/usr/binの下など)を侵蝕することがあると嫌だからです。 次のように環境変数を設定しておくと、普通に使えます。
$ export GEM_PATH=/usr/local/ruby
$ export PATH=${GEM_PATH}/bin:$PATH
/usr/local/ruby以下のrails1.xは残したまま、rails2.xをインストールすることにしました。ほぼ同じ方針で次のようにしました。
# mkdir /usr/local/ruby2 # chown inoue:users /usr/local/ruby2 $ gem install rails -i /usr/local/ruby2 --include-dependencies
環境変数(GEM_PATH)を切替えるだけで使えるはずです。railsの実行は問題なく動きました。が、script/generateで次のエラーがでました。
$ script/generate Rails requires RubyGems >= 0.9.4 (you have 0.9.0). Please `gem update --system` and try again.
etchのパッケージのgemのバージョンは次のようになっています。
$ dpkg -l|grep gems ii libgems-ruby1.8 0.9.0-5 libraries to use RubyGems, a package managem ii rubygems 0.9.0-5 package management framework for Ruby librar
etchをアップグレードする気はありません。エラーメッセージにある gem update --system の詳細は不明ですが、Debianでパッケージ管理されたgemを、独自にアップグレードするのは避けたいところです(パッケージ管理混ぜるな危険の法則による)。
結局、gemのソースを持ってきて、自分でインストールすることにしました(/usr/local/ruby2の下にインストール)。
$ cd rubygems-1.0.1 $ ruby setup.rb --prefix=/usr/local/ruby2
環境変数の設定は次のようにします。
$ export RUBYLIB=/usr/local/ruby2/lib
$ export GEM_PATH=/usr/local/ruby2
$ export PATH=${GEM_PATH}/bin:$PATH
これでscript/generateが動くようになりました。
と思ったら、なんと今度はrailsが動かなくなりました。
$ rails /usr/local/ruby2/bin/rails:17: undefined method `require_gem' for main:Object (NoMethodError)
require_gemがgem1.xで無くなっているのが原因です。APIを勝手に変えるgemに問題があるのか、gem1.xで無くなるAPIに依存しているrailsに問題があるのか、それはともかく微妙な混沌ぶりに脱力します。
結局、gemにこだわりもないので、rubygems-0.9.5にダウングレードしました。次のような警告はでますが、無視します。
$ rails /usr/local/ruby2/bin/rails:17:Warning: require_gem is obsolete. Use gem instead.
rails2を少しいじってみました。script/scaffoldで作られるコントローラのコードがこんなです。
def index
@my_models = MyModel.find(:all)
respond_to do |format|
format.html # index.html.erb
format.xml { render :xml => @my_models }
end
end
いきなりムズいです。Rubyを知らない人が見たら、ファイル名が並んでいると間違えそうです。ちなみにrespond_toのコードも、冒頭からいきなり
def respond_to(*types, &block) raise ArgumentError, "respond_to takes either types or a block, never both" unless types.any? ^ block
respond_toをブロック付きで呼び出すと、仮引数の &block に値が入るので、blockの評価がtrueになります。ブロック以外の引数を渡すと、*types に値が入ります(アスタリスクの意味は、可変長引数を配列で受ける、です)。この時、types.any? はtrueになります。unless以下は XOR をしているので、両方falseもしくは両方trueの場合に例外を投げます。
respond_to の動作もなかなかエキセントリックです(format.htmlの呼び出しで成功した時、format.xmlが呼ばれない処理の流れは、ソースを見ても良く分かりません)。
絶対、RubyはJavaより難しいと思います。
(*) あまり保守的すぎるのも問題かと思い、せめてemacsぐらいはと、CVSの最新版ソースを手元に持っています。最近はDBus周りのコードのコミットが目につきます。もっとも常用しているemacsはいまだにemacs21ですが...
- Category(s)
- カテゴリなし
- The URL to Trackback this entry is:
- http://dev.ariel-networks.com/Members/inoue/rails2-first/tbping